
Originally published on DZone on October 17, 2018.
TL;DR: Compare sections 5) CONSUMERS OF THE API of the two files in this diff, and see which one you find more readable.
Introduction
The idea for writing this article came to me after a discussion on DZone about the Filterer Pattern. The discussion concerned the validity of introducing subtype polymorphism (instead of parametric polymorphism) into a composition-based design.
The goal of this article is to present a case where subtype design works better than parametric design. From this, I draw a conclusion that, in certain context, a subtype design is better than a parametric one. However, it is a non-goal of this article to speculate how often such context occurs in the real world (I have encountered such context only twice so far).
I decided that, as an example for this article, I will choose a problem from the Natural Language Processing (NLP) domain. The specifics of this domain are not of much importance here, but the problem domain itself needs to be complex enough so that the benefits and costs of subtyping vs. parametrization can be demonstrated.
It took me a long time to determine the bounds of the sample problem and to prepare the sample code for this article, and I am still not entirely satisifed. I tried hard to strike a balance between comprehensibility (as simple as possible) and exemplification (as complex as necessary to make my point).
Problem Domain
This section may be skimmed by a reader who has some NLP/linguistic background or simply does not feel the need to understand the ubiquitous language of the domain.
Natural Language Processing (NLP) is a fairly large domain, but here, we will be concerned with the following, narrow subdomain:
- Text: a list of sentences + the language of the text.
- Sentence: a “textual unit consisting of one or more words that are grammatically linked,” and whose syntax is parsed to:
- constituent tree: as per phrase structure grammar (with constituent types different for every language);
- list of dependencies: as per dependency grammar (with dependency types different for every language).
- Token: a single word, number, or punctuation mark; a token can be tagged with:
- part of speech (PoS): a “category of words that have similar grammatical properties” (different for every language).
Example:
| Text | Sentences | Tokens |
| I said it. Have you heard? | 1) I said it. 2) Have you heard? | 1) I 2) said 3) it 4) . 5) Have 6) you 7) heard 8) ? |
As a result, we can distinguish the following stages of processing a text:
- Tokenization: splitting of text into tokens.
- Sentencization*: grouping of tokens into sentences.
- Tagging: assigning a part of speech to every token.
- Parsing: assigning a syntax representation (constituent tree + dependencies) to every sentence.
* This term is not commonly used, but it fits so nicely into the pattern: token → tokenize; sentence → sentencize.
Problem
The problem consists in modeling the domain (i.e. processed text representation) for:
- Producers, which:
- take raw text as input,
- return an appropriately processed text representation as output,
- have only one or two implementations;
- Consumers, which:
- take an appropriately processed text representation as input,
- contain business logic expressed using these representations,
- have a large number (several dozen) of implementations.
In a way, the problem may be viewed as providing a utility API for the use in consumers, or even as designing a domain-specific language (DSL) for the consumers.
Problem Requirements
The following requirements need to be taken into account:
- Language support: English (full) + German (tagging only) + other potential languages.
- Text can exist in any stage of processing (i.e. unprocessed, tokenized, or tokenized+sentencized).
- Each sentence of a given text can exist in any stage of processing* (i.e. unprocessed, tagged, or tagged+parsed).
* Why such requirements? One of the reasons is that some processing stages, like tagging and parsing, are quite time-consuming, so we want to avoid them whenever possible.
Problem Space
The problem can be viewed along the following dimensions:
- X-axis: textual unit (token – sentence – text),
- Y-axis: processing stage (unprocessed – tokenized – sentencized – tagged – parsed),
- Z-axis: language (generic – English – German).
The problem space is illustrated below:

Proposed Solution
The solution here is proposed along the dimensions defined in Problem Space. By “solution,” I mean primarily contracts (i.e. interfaces), and only secondarily – implementations (i.e. classes).
X-Axis: Textual Unit
This axis can be easily modeled using composition (or aggregation, depending on how we view it) as:

Y-Axis: Processing Stage
This axis is a bit harder to model because not all textual units (X-axis) are present in all processing stages (Y-axis), as shown below (cf. Problem Space):
| Y-axis ╲ X-axis | text | sentence | token |
| unprocessed | ✓ | ||
| tokenized | ✓ | ✓ | |
| sentencized | ✓ | ✓ | ✓ |
Furthermore (cf. Problem Requirements), a text can be only partially tagged/parsed (i.e. only some of its sentences can be tagged/parsed).
As a result, I decided to model this axis using subtyping:
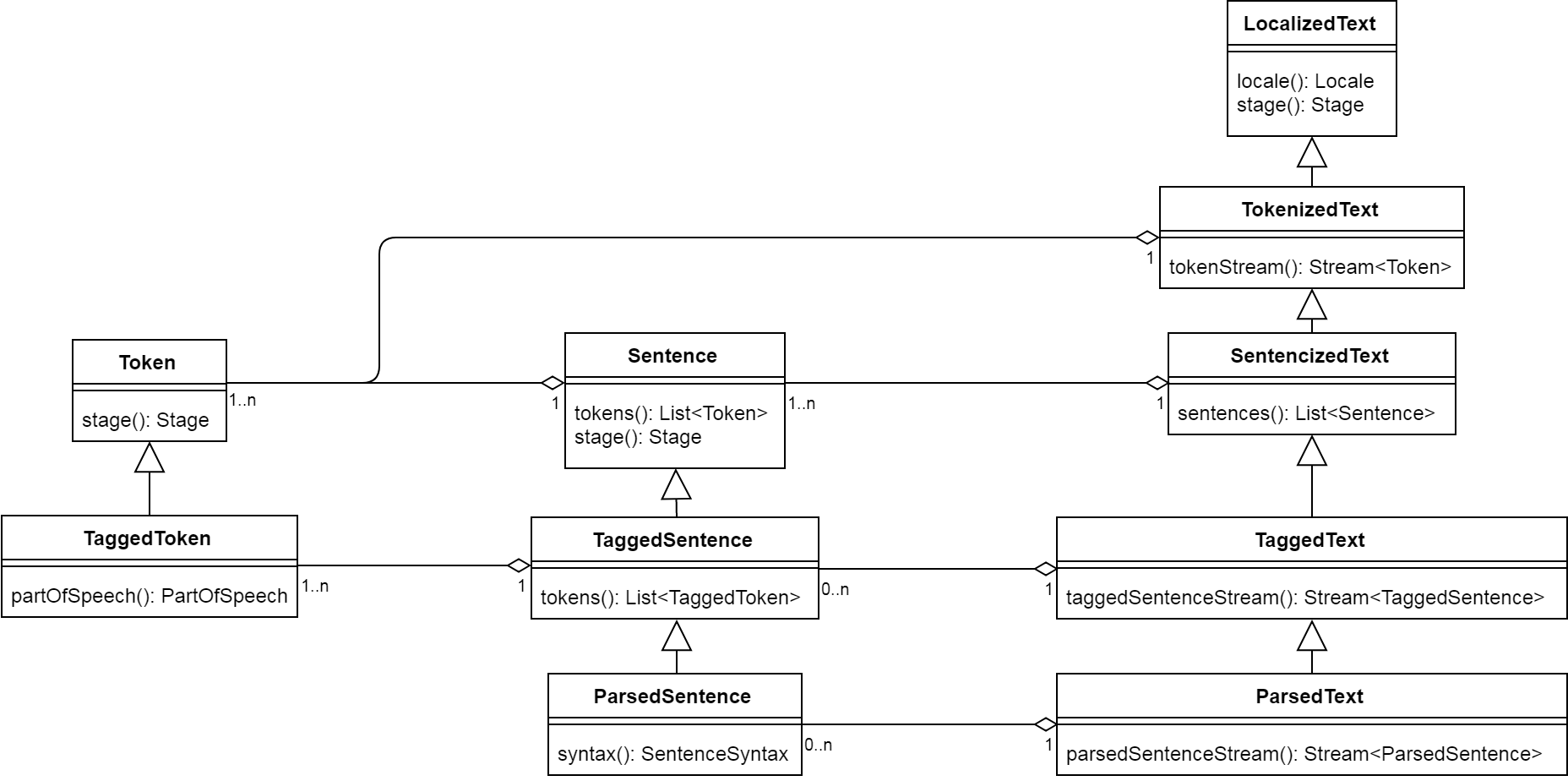
I could not find any better way to model this axis (neither parametrization nor composition seemed to fit here), but I encourage the reader to suggest a better way should they know of any.
Note that:
- the hierarchy was coupled with a
Stageenumeration so that the stage can be checked without resorting toinstanceof; - methods
taggedSentenceStream()andparsedSentenceStream()were added alongside methodsentences()instead of overriding it (cf. Problem Requirements, point 3); SentenceSyntaxprovides a constituent tree and dependencies (cf. Problem Domain, point 2).
Z-Axis: Language
This axis is the most problematic one. Modeling of this axis (i.e. modeling various languages) is the key point of this article.
Let us consider the options we have, keeping in mind that parts of speech, constituent types, and dependency types differ between languages:
- Composition: does not seem to be applicable in this case.
- Parametrization: can be applied but would require up to three type parameters (
P: part of speech,C: constituent type,D: dependency type). - Subtyping: can be applied but would require several new subtypes per every language (e.g.
TaggedToken→EnglishTaggedToken,GermanTaggedToken).
In this article, we will compare solutions 2 (Parametrization) and 3 (Subtyping).
Solution 2 for Z-Axis: Parametrization
This solution does not require adding any new types to the type hierarchy. Instead, it requires adding type parameters to the types shown below:
- Tagged:
TaggedToken→TaggedToken<P extends PartOfSpeech>TaggedSentence→TaggedSentence<P extends PartOfSpeech>TaggedText→TaggedText<P extends PartOfSpeech>
- Parsed:
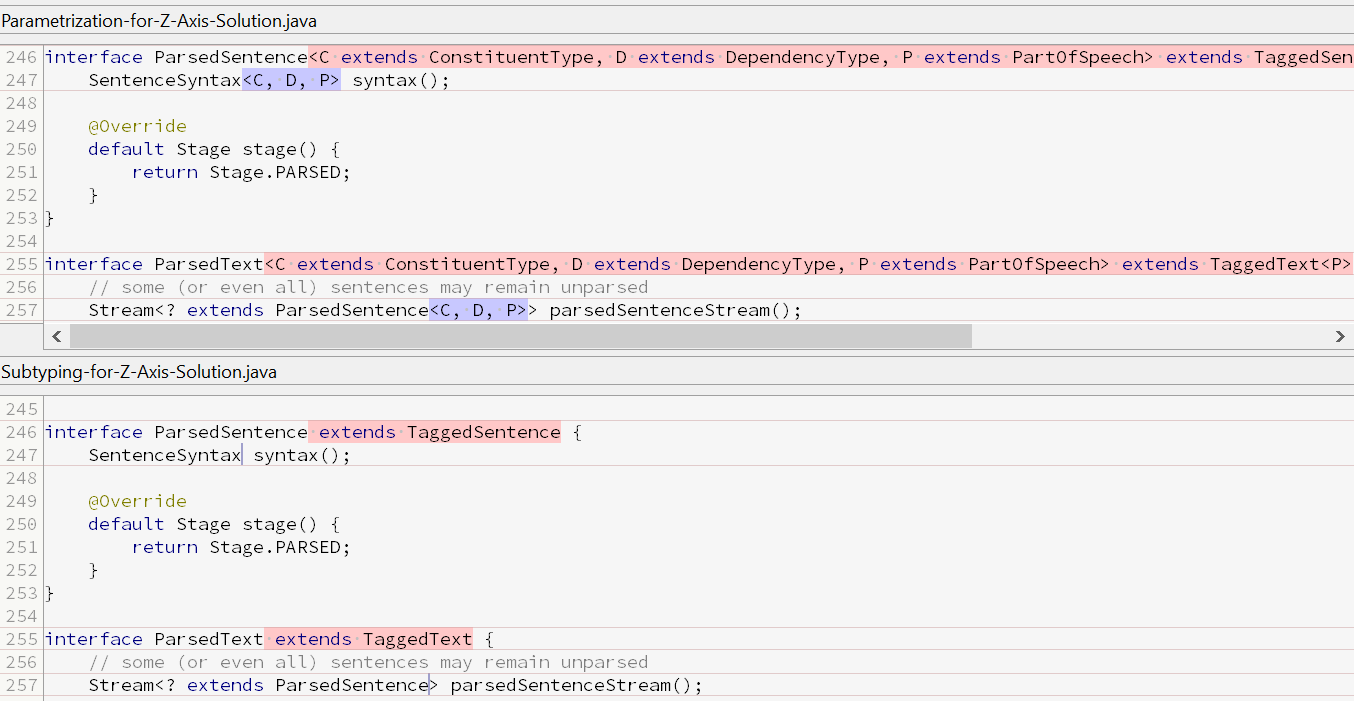
ParsedSentence→ParsedSentence<C extends ConstituentType, D extends DependencyType, P extends PartOfSpeech>ParsedText→ParsedText<C extends ConstituentType, D extends DependencyType, P extends PartOfSpeech>
As seen above, the parsed types become unwieldy with three bounded type parameters (note that we need P in parsed types because ParsedSentence extends TaggedSentence).
This results in the same type hierarchy as presented for the X-Y-axes (see Y-Axis: Processing Stage).
The minimal working example (MWE) for this solution can be found in the following self-contained GitHub Gist file (this file is compilable on its own under JDK 8+).
Solution 3 for Z-Axis: Subtyping
This solution, on the other hand, requires adding the following new subtypes for every language (where {Lang} is a placeholder for a given language):
- Tagged:
{Lang}TaggedTokenextendsTaggedToken{Lang}TaggedSentenceextendsTaggedSentence{Lang}TaggedTextextendsTaggedText
- Parsed:
{Lang}ParsedSentenceextends{Lang}TaggedSentence,ParsedSentence{Lang}ParsedTextextends{Lang}TaggedText,ParsedText
In our scenario, this results in the following (quite complex) type hierarchy:
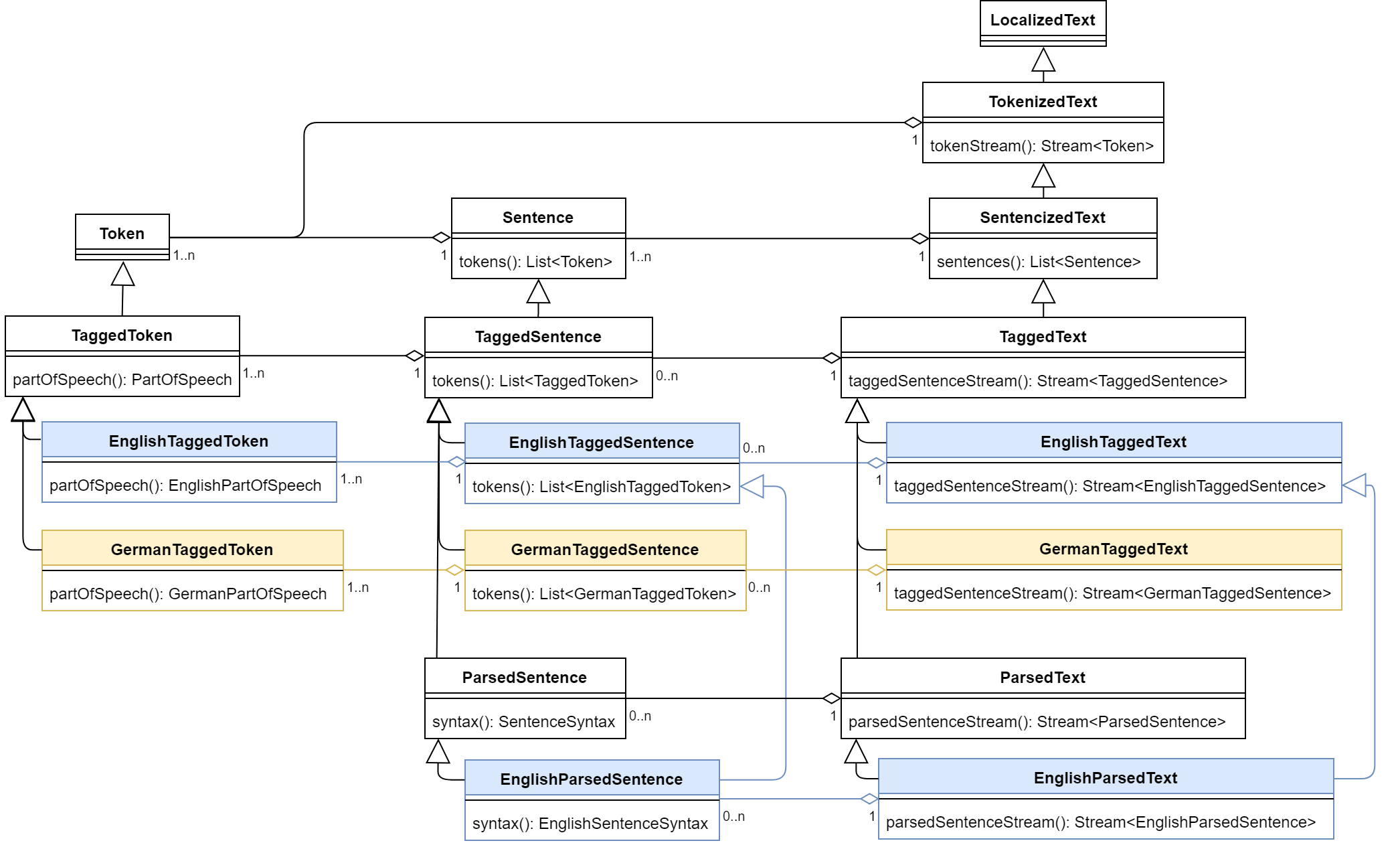
The minimal working example (MWE) for this solution can be found in the following self-contained GitHub file.
Comparison of Minimal Working Examples
Source Code Length
The differences in source code length per sections of the MWEs are presented below:
| Source code length of the MWE | Solution 2: Parametrization | Solution 3: Subtyping | Difference |
| Section 3) Domain model | ~2700 chars | ~4400 chars | +60% |
| Section 5) Sample consumers | ~5000 chars | ~4400 chars | -10% |
Note that the differences are slightly biased because:
- Implementations of domain model are absent (sections 3 of the MWE);
- Only a few of the several dozen consumers are present (sections 5 of the MWE).
That said, it seems safe to assume that — in all cases — solution 2 (parametrization) would result in, overall, less code than solution 3 (subtyping).
Source Code Differences
The full diff between the two MWEs can be viewed here (an HTML page generated by SmartGit).
Below, a few interesting parts of this diff are presented (screenshots from SmartGit). It is important to note that:
- Readability differs significantly between the two solutions (especially in consumers);
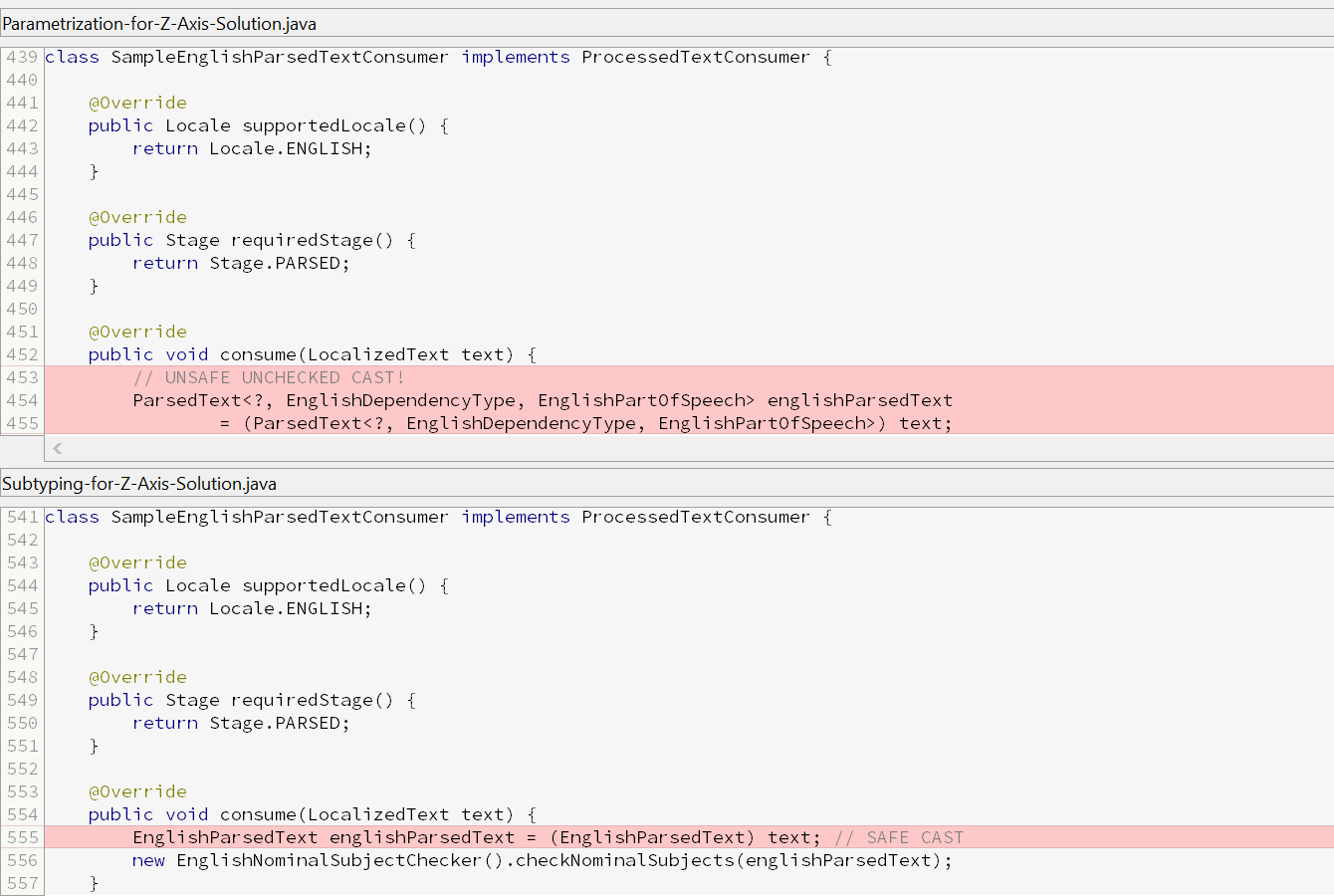
- Solution 2 (parametrization) can result in an unsafe, unchecked cast in an indirect consumer, which can be seen in the last screenshot below.
Domain Model (ParsedSentence + ParsedText)
Direct Consumer (EnglishNominalSubjectChecker)
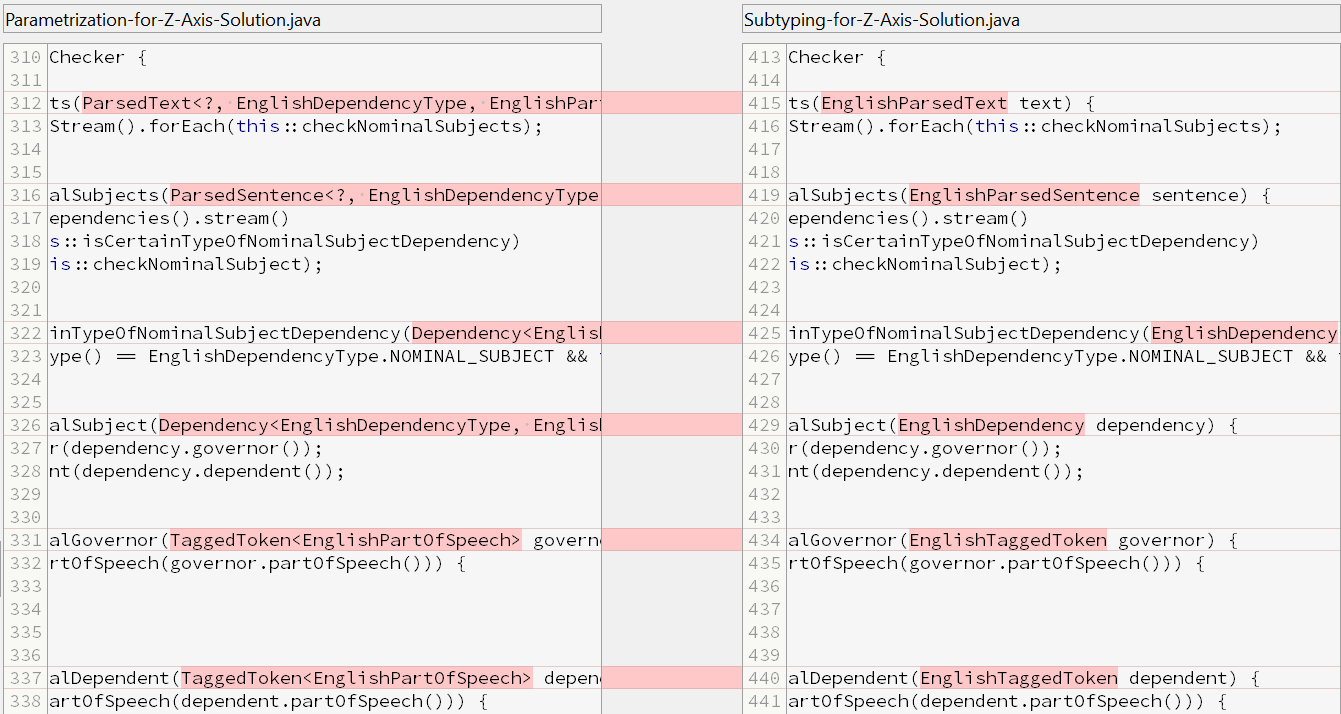
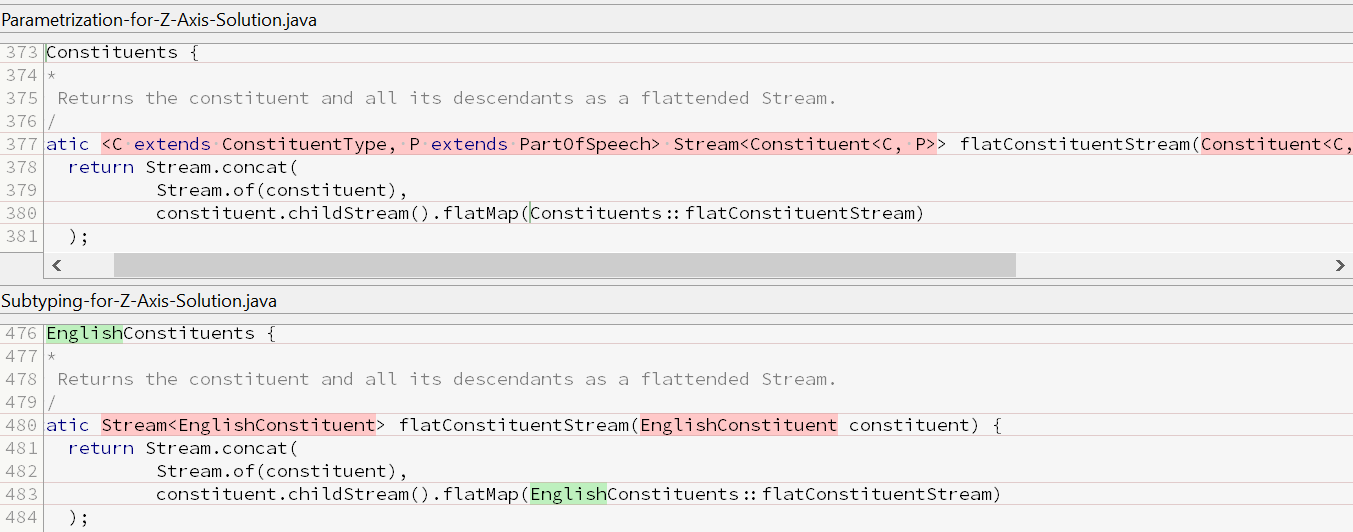
Helper Class (Constituents/EnglishConstituents)
Indirect Consumer (SampleEnglishParsedTextConsumer)
Conclusions
Which Solution to Favor: Specific Case
I believe that – for the specific problem that I presented in this article – it is better to choose subtyping over parametrization. The reasons are:
- The readability in the consumers is of utmost importance; as stated in the Problem section, the consumers contain business logic.
- There are only two languages to model, and it is unlikely there will ever be more.
- The subtype model is semantically closer to the domain than the parametric model (e.g.
EnglishTaggedTokenvs.TaggedToken<EnglishPartOfSpeech>). - The subtype model is actually quite intuitive and easy to use — it is the design and implementation of such model that is the greatest nuisance.
Which Solution to Favor: General Case
By default, parametrization should be favored over subtyping because parametrization is succint, versatile, and easier to maintain.
However, in a certain context (defined below), subtyping should be favored over parametrization. This context can be recognized when all the requirements below are met:
- Brevity and readability at use site (here: in consumers) are much more important than at declaration site (here: in domain model), especially if use site contains business logic.
- There are only a few different types to model using subtyping (here: languages). The reason for this is the burden of adding a new type to the subtyping solution, which is substantial.
- There is little need for parametrized methods that transform one of the types, as explained in Source Code Differences: Helper Class above. In case of parametrization, one such method is enough; in case of subtyping, though, one method per every type is needed.
- Any other requirements that I may have forgotten about (if you notice them, feel free to point them out in the comments below).
Appendix
Here, I put everything that seemed non-essential to the article but that I still wanted to include for the most inquisitive readers.
Existing Solutions
There are several NLP libraries for Java, but I do not know of any that meets the Problem Requirements specified above.
Below, I prepared a summary of modeled types and rejection reasons for three such libraries:
- Stanford CoreNLP
Domain model: Token, Sentence, Document | TaggedWord | Constituent, Dependency
Rejection reason:String-based PoS tags and constituent/dependency types; mutability. - Apache OpenNLP
Domain model: Tokenizer*, SentenceDetector* | POSTagger* | Parse
Rejection reason:String-based tokens, PoS tags, and constituent types; no dependency parsing; mutability. - Alias-i LingPipe
Domain model: Tokenizer*, SentenceModel* | Tagging
Rejection reason:String-based tokens and PoS tags; no syntax parsing.
* Type corresponding to the domain object provider since the domain object is absent – String is used instead.
Implementation Note
Note that in both cases (i.e. parametrization and subtyping for Z-axis), the implementations (which are not included in the MWEs) will be based on parametrization. Let us compare this in an example of implementing TaggedToken.
First of all, we have a common implementation of PlainToken:
final class PlainToken implements Token {
private final String text;
private final int startOffset;
private final int endOffset;
private final TokenType tokenType;
// constructor + getters
}Then, in case of parametrization for Z-axis (solution 2), the implementation of TaggedToken is quite straightforward:
final class PlainTaggedToken<P extends PartOfSpeech> implements TaggedToken<P> {
private final PlainToken plainToken;
private final P partOfSpeech;
// constructor + getters
}However, in case of subtyping for Z-axis (solution 3), we simply have an AbstractTaggedToken that is almost identical to PlainTaggedToken, and then we derive trivial subclasses from it:
abstract class AbstractTaggedToken<P extends PartOfSpeech> implements TaggedToken {
private final PlainToken plainToken;
private final P partOfSpeech;
// constructor + getters
}
final class PlainEnglishTaggedToken extends AbstractTaggedToken<EnglishPartOfSpeech> implements EnglishTaggedToken {
// constructor
}
final class PlainGermanTaggedToken extends AbstractTaggedToken<GermanPartOfSpeech> implements GermanTaggedToken {
// constructor
}In a way, the subtyping implementations serve as kind of type tokens (cf. Guava’s TypeToken).
When Would Subtyping Solution Be Redundant
Note that the subtyping solution would be nearly completely redundant if Java had:
- Reified generics (something along these lines would do).
- Global type aliases (like in Kotlin).
- Shorthand unbounded wildcard notation instead of raw types:
- For example, if
TaggedToken<P>were a parametrized type,TaggedTokenwould simply be shorthand forTaggedToken<?>(unbounded wildcard type) instead of being a raw type.
- For example, if
If all those conditions were met, we would be able to:
- Define parametrized types and their aliases (e.g. parametrized type
TaggedToken<P extends PartOfSpeech>andEnglishTaggedTokenas an alias ofTaggedToken<EnglishPartOfSpeech>); - Perform safe casts (e.g. from
TaggedToken<?>toEnglishTaggedToken).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
One thought on “Complex Subtyping vs. Parametrization”
For reference: discussion on reddit.